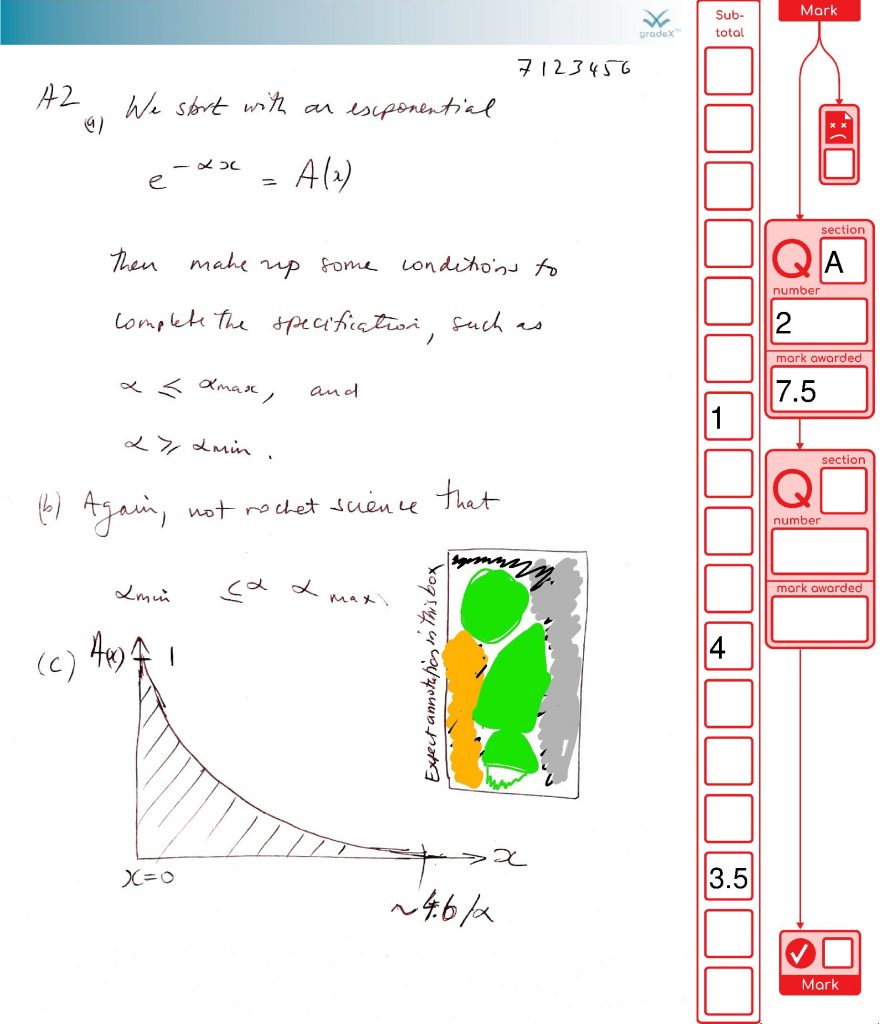
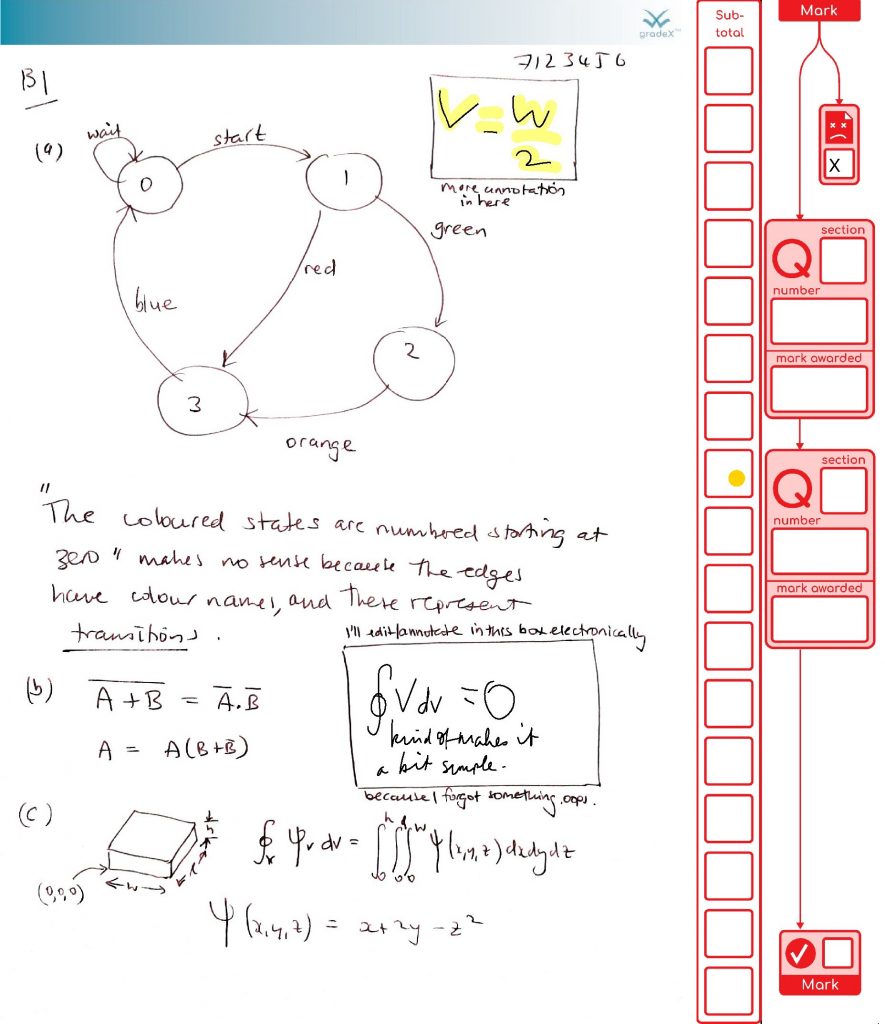
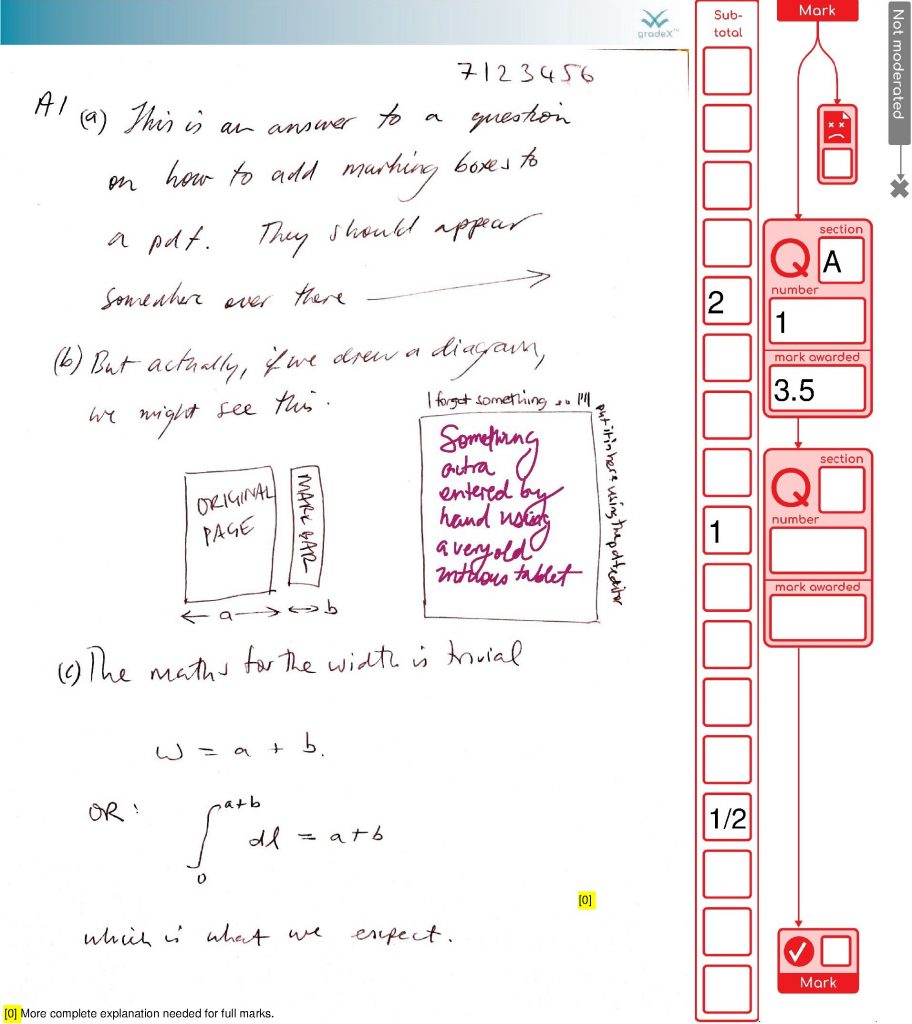
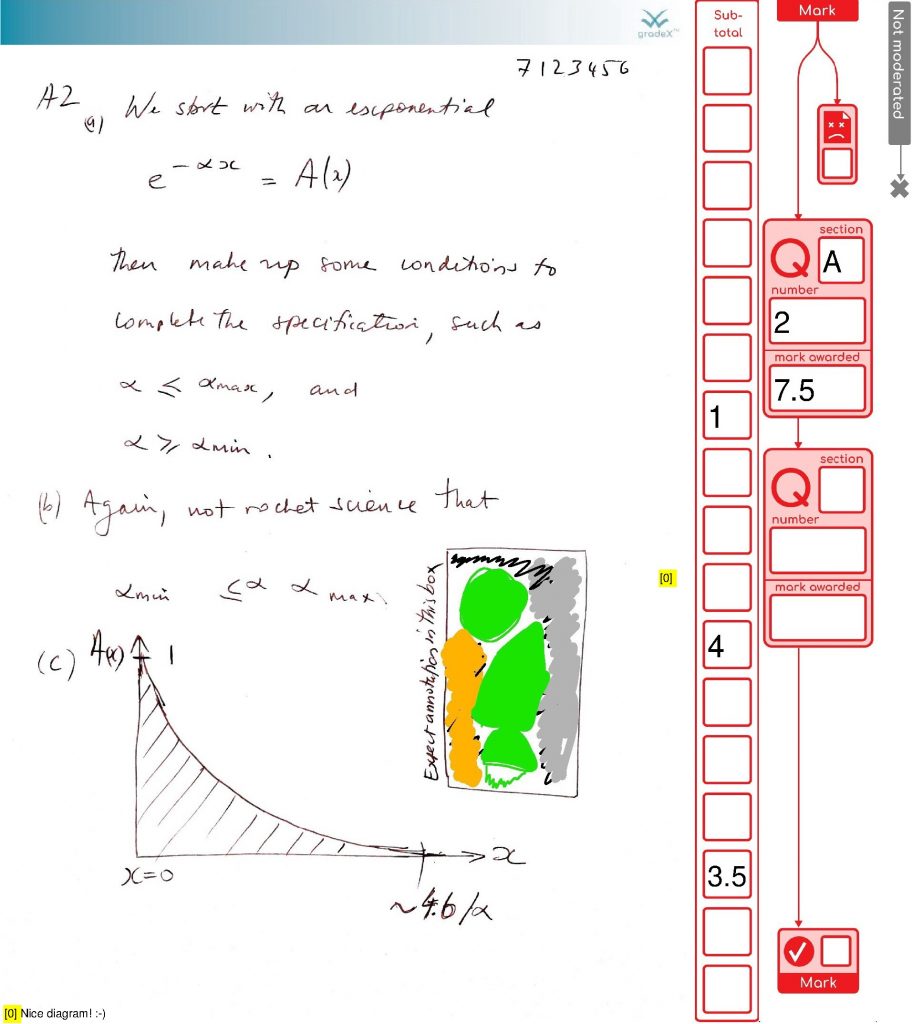
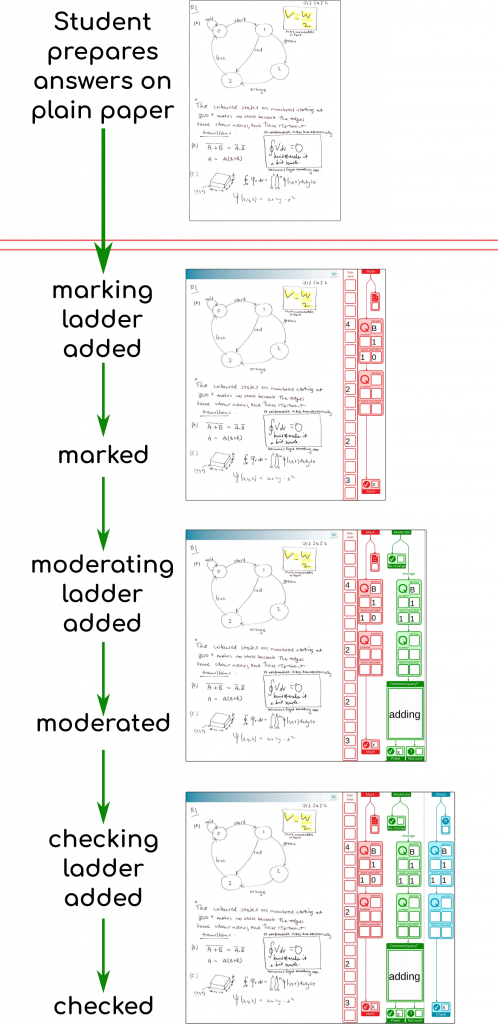
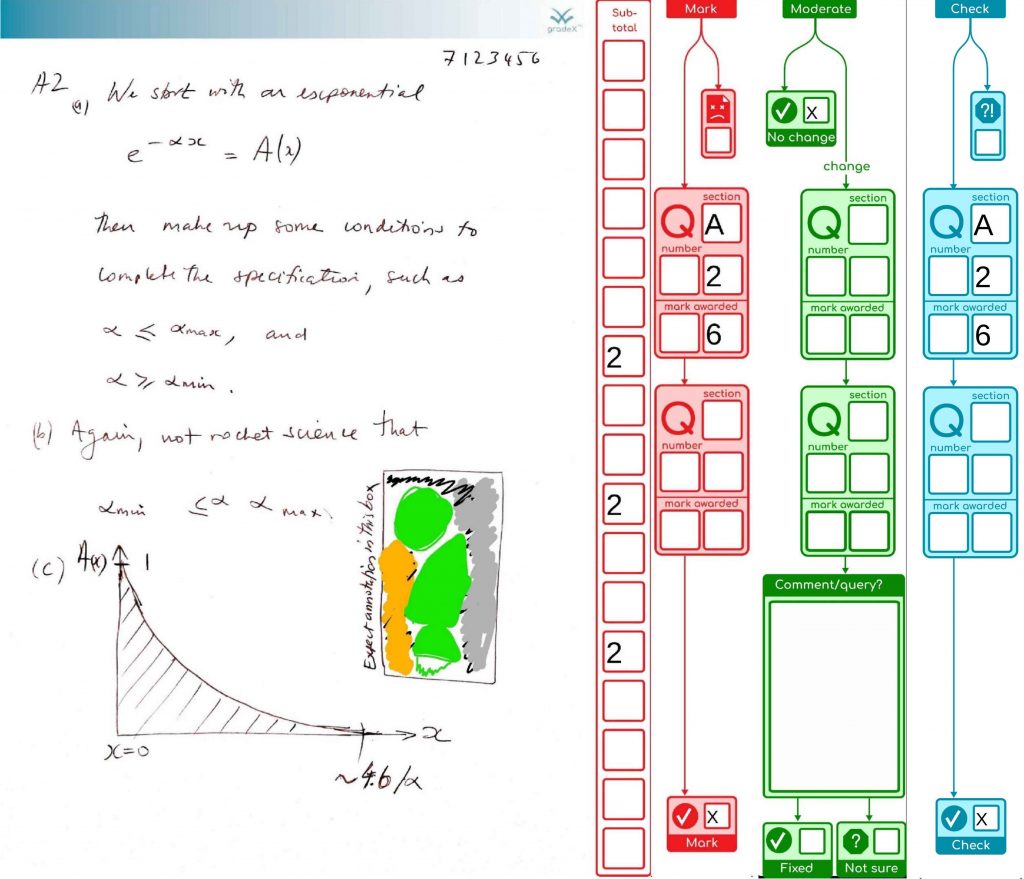
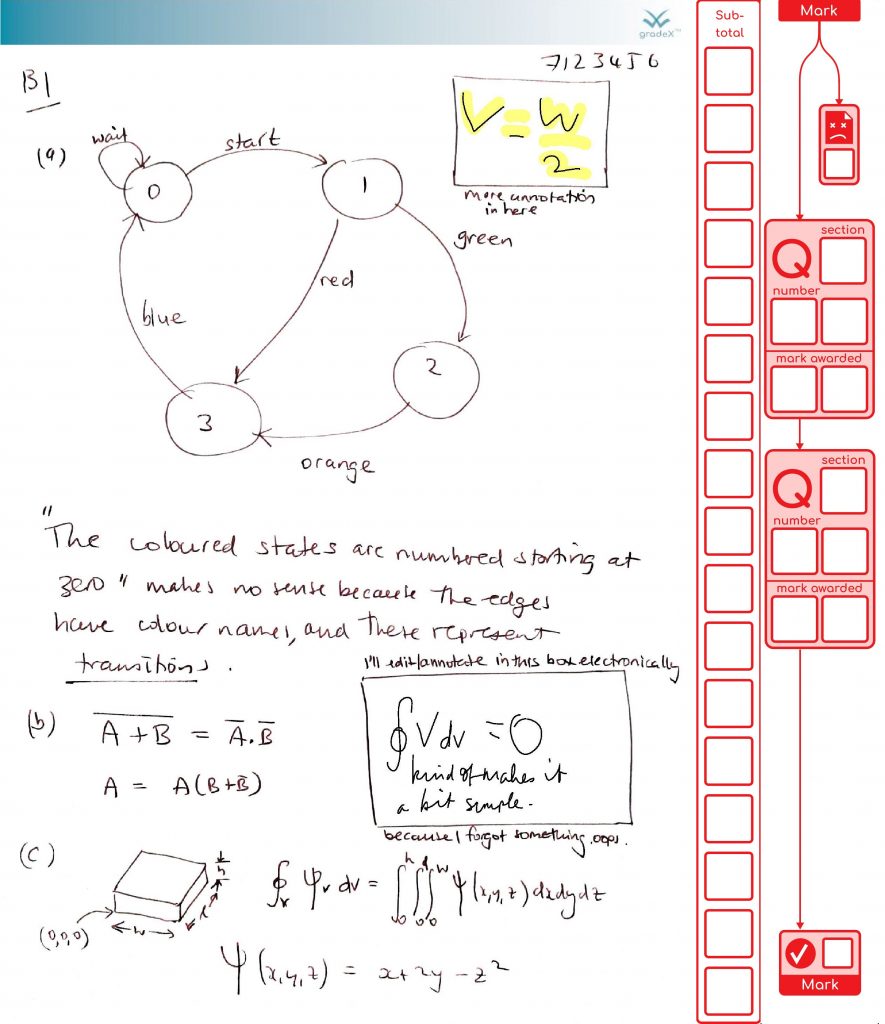
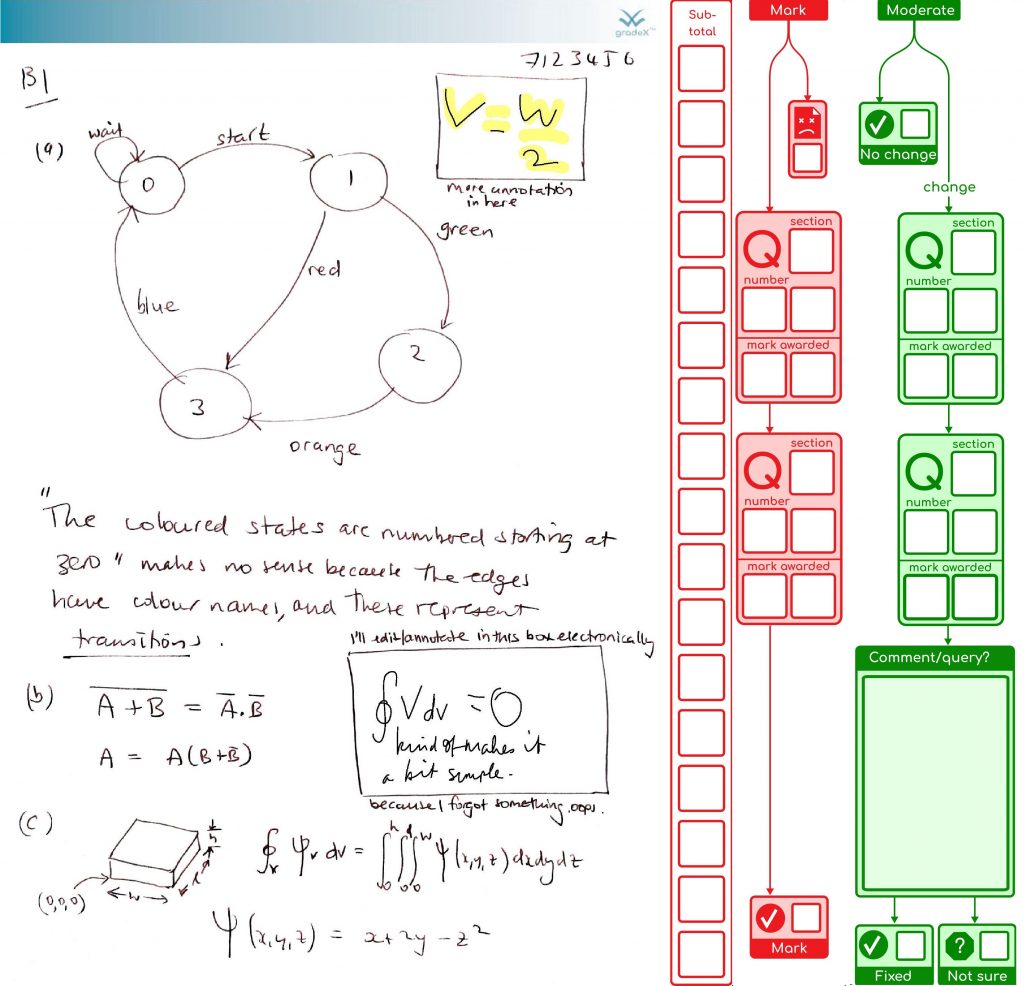
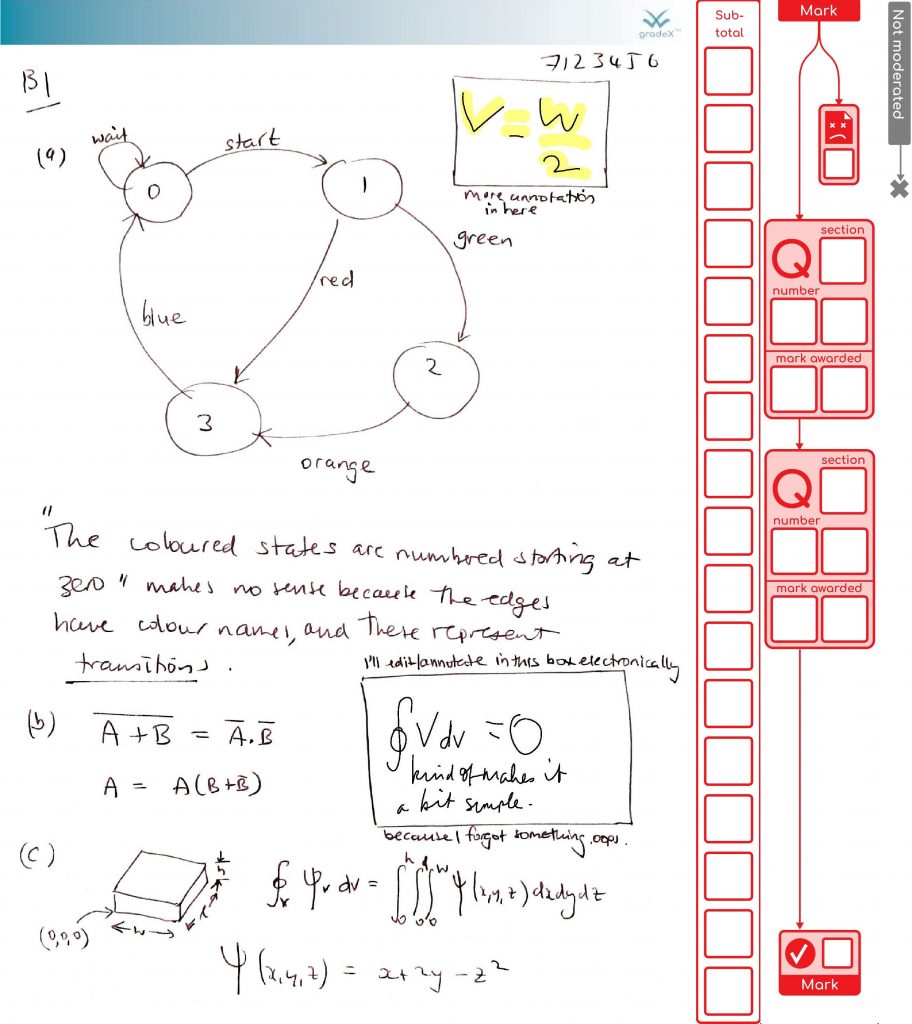
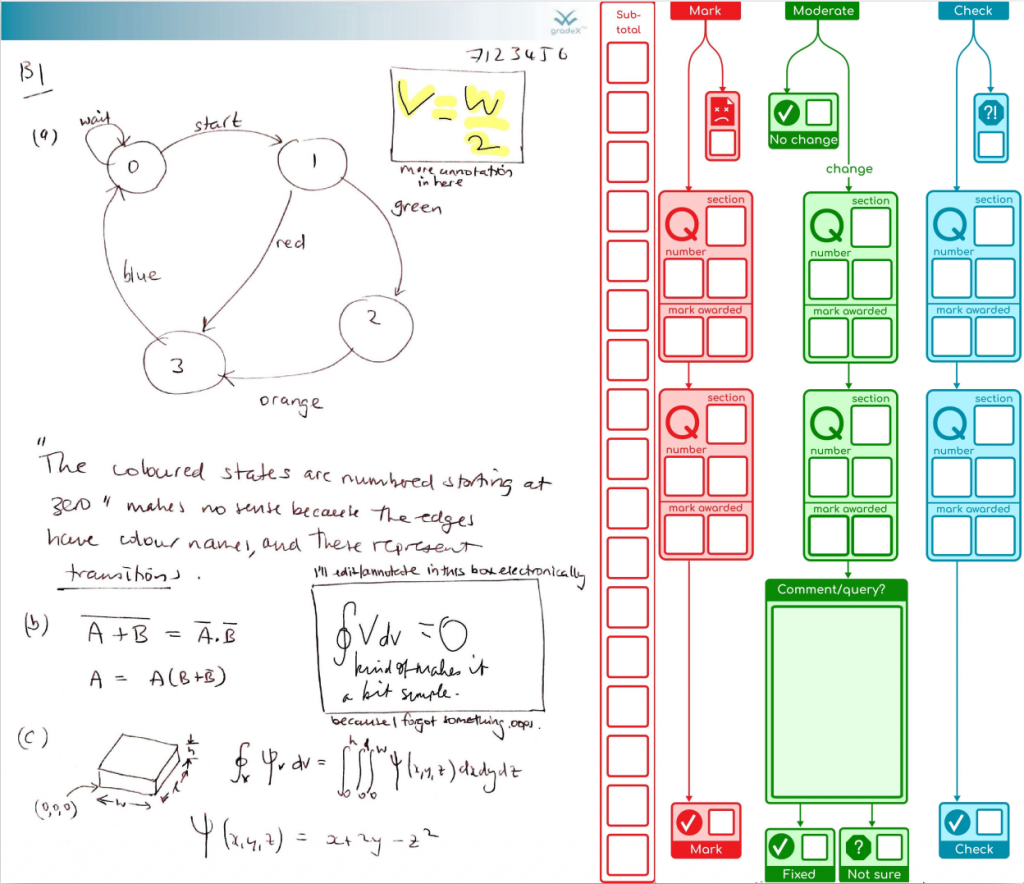
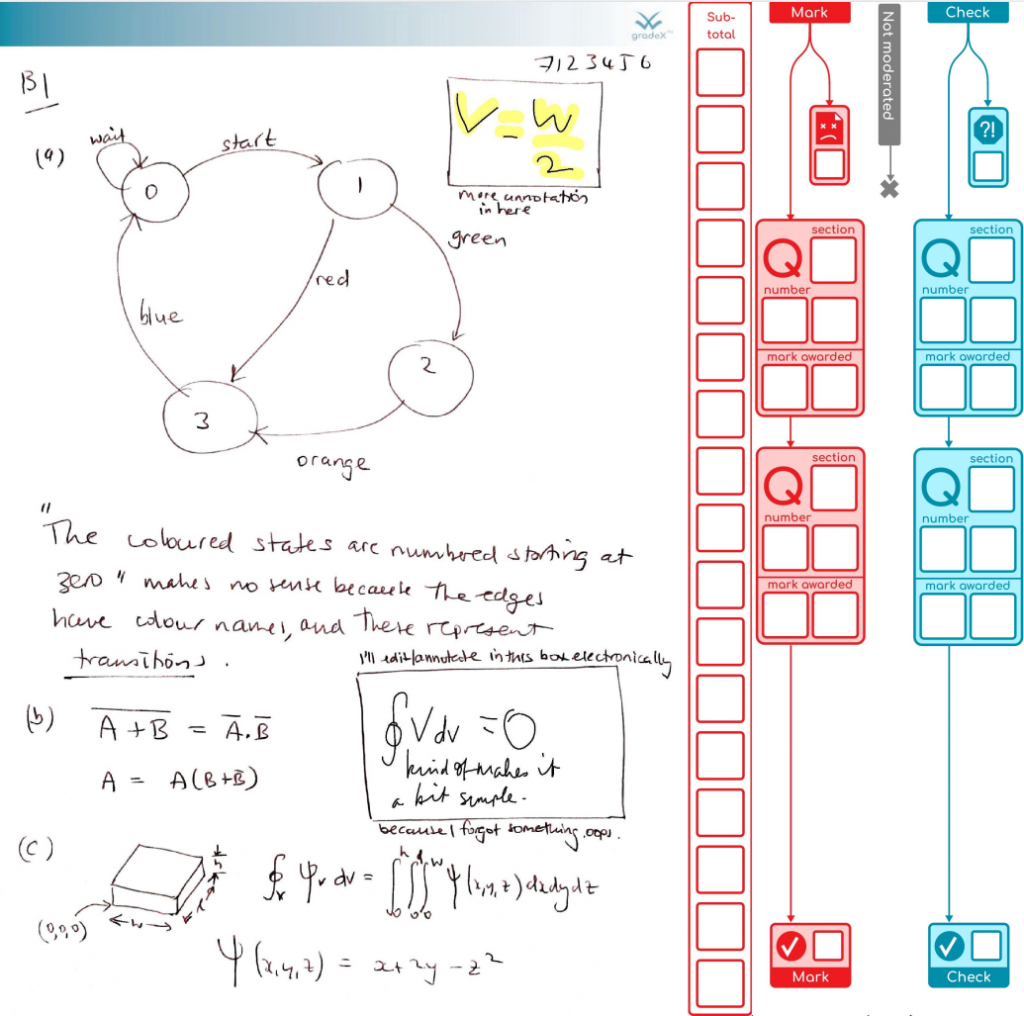
We’ve finished processing the exams in my organisational unit for this exam diet. It all went well. So we’re done. Finally! Here are the stats on what the system achieved (with the help of 48 combined cores of processing and two additional staff doing processing for around the last five weeks, working together to support our the exams team). This system was also used by another organisational unit as well, as their default option.
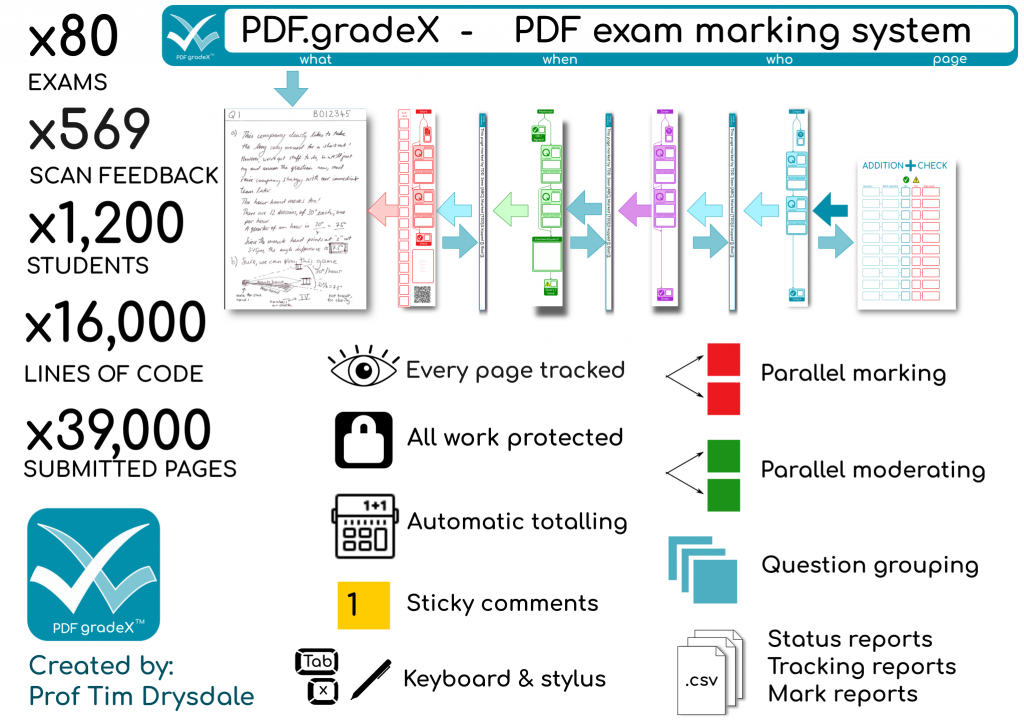
I’ve learned plenty about our behind-the-scenes exam processes and the limitations of PDF – this was definitely the right solution for us, for the emergency situation we were in, despite the immense amount of work to create it. It de-risked the process by keeping everyone’s work safe from edit conflicts between students and staff, and between staff members assessing it, as well as being backwards-compatible with the old Mk1 Human so we could revert to the pain of a fully manual process at any time if we hit insurmountable problems (which we didn’t in the end).
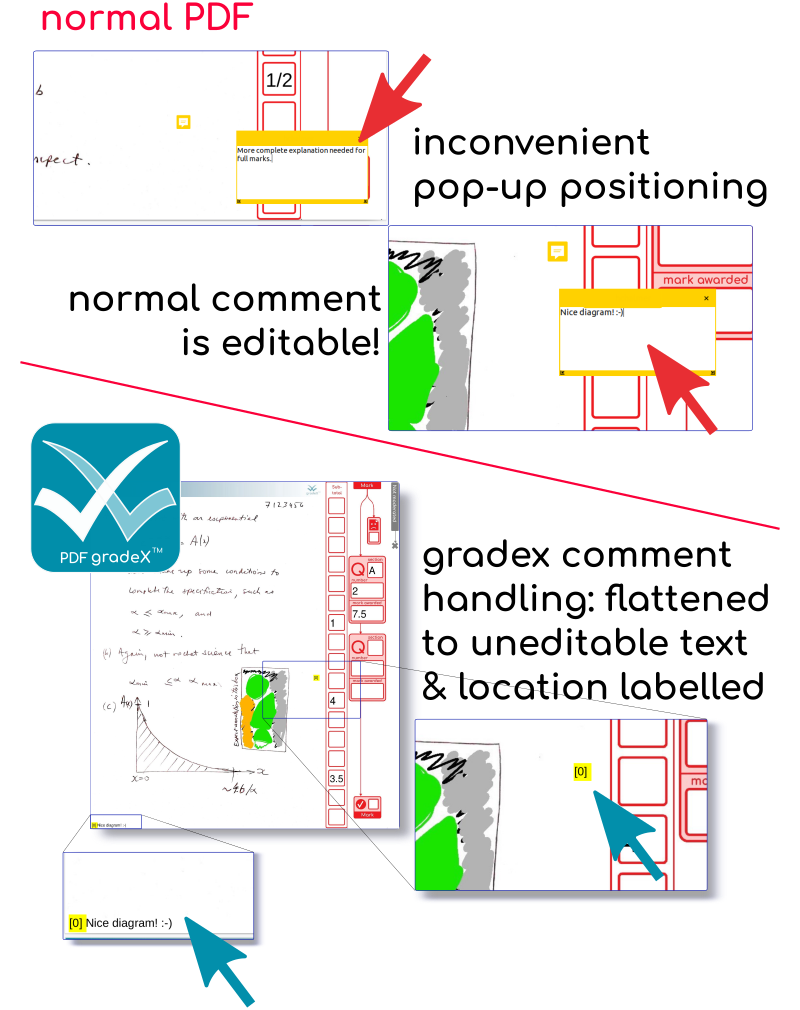
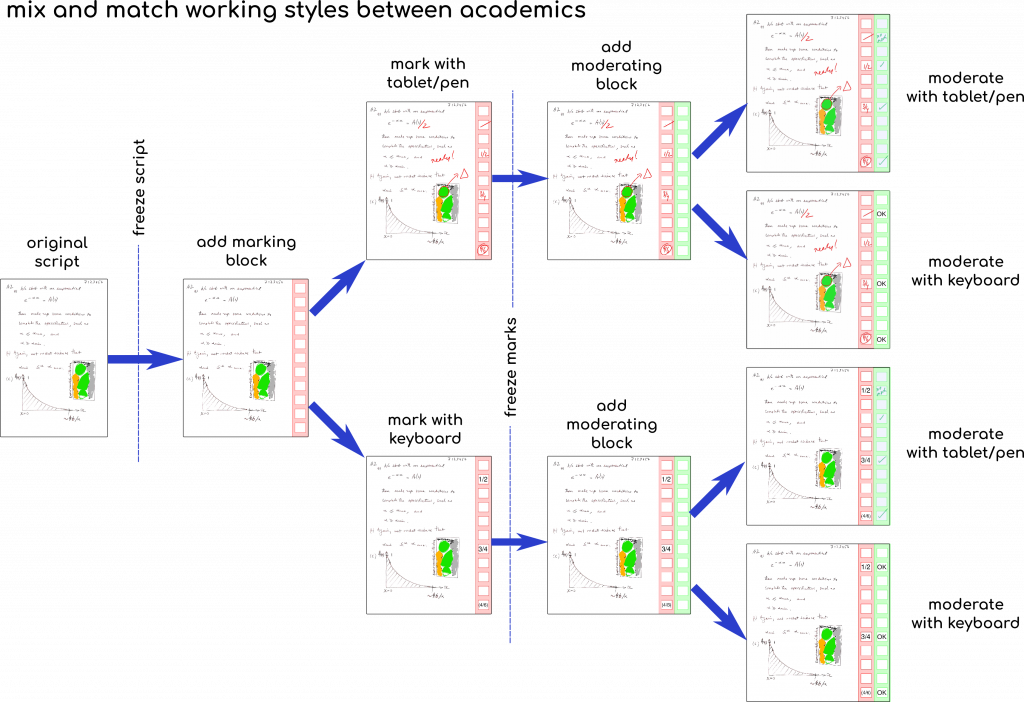
Working with the PDF ecosystem reminded me why I prefer browser-based solutions – you can interact with the user and keep them on track.
Me
An online electronic marking system is the way to go for us in the future. That’s possible for us now that we’ve taken that first step. Using a digital process that mapped exactly onto our existing workflow avoided a possible barrier to adoption of a new approach. Now our staff have seen the benefit of a digital workflow, we can have a chat about adopting a fully online system – especially since colleagues ran limited trials with other systems (interestingly, using this system to pre-process files before feeding them into the competition). The issues I ran into with the PDF ecosystem itself mean I don’t think a better user experience overall is possible no matter how good the underlying library that you use to work with PDF – you are still at the mercy of the interpretation of the specification for PDF by the viewing tools used by the staffs. We topped out on the quality of that experience, so time to move back to my favourite domain – the browser.
So, as you might guess, eyeing up the browser takes us smack bang into the territory already served by some existing tools. To compete or not to compete? This was not an easy decision because there is a really strong ethical benefit to operating assessment software from an open-source academic team. It provides an opportunity to fund the development from teaching income, and avoid the allure of monetising the student data. By the way, the reason that is even an issue for the edtech sector is that if you have shareholders, you have a legal obligation to do right by them, and that makes it rather difficult to leave money on the table (money you might need to stay in business, to grow, or to make a suitable exit for the founders). We can get around that by using a different funding model.
On the other hand, is it worth the effort to develop a tool which doesn’t monetise student data, but still (only) achieves the same (limited) academic outcomes? And how do you feel about that when you step back and realise you’d really like to see a bunch of change in the way things are done in that educational sector? Is that a reason to aim for a seat at the table now, just so you can try and make change later? Or would that be so much effort you’d never get to the transformative stuff? And is the context in which you’d be operating sufficiently flexible that you can slot the transformative stuff into whatever you are doing, or might it not fit?
There’s a really excellent discussion of the difference between migration online, and transformation online, in assessment systems here – an article suggested to me by Jen Ross, during a conversation we were having with Tim Fawns, who also added great stuff to my thinking (which I am not re-iterating here simply because it needs a proper writing out!)
There is no bald statement of the right path in that paper, but there is certainly a strong indication of the risk of getting bogged down in migration instead of doing transformation. What sort of development journey will evaluative judgement, contract grading, accept-revise, student-in-control grading, and various other practices need in order to flourish – and what role will digital assessment play – if any? Can you make a logical sequence of technical development moves to get from online “commodity” grading to the transformative stuff? Or are they paths that do not cross? In which case, what happens if you try to start with migration? What if you think there might be a way to do all of this without any traditional grading at all? (Health warning: people of a traditional disposition, look away now. Too late? Did I already say that? Sorry not sorry). Ok that’s clearly an extreme provocation. But it is a thought process I went through to offset the dangers of sunk-cost fallacy and train-track thinking (i.e. trying to avoid the pitfall of “I’m doing this, so I shall do more of this”).
How to resolve this in the case of future tools in the gradex ecosystem? Since academics who care about teaching, care about improving the experience for students, it seems a greater good can be served by focusing immediately on new practices that lead to better experiences for students and putting up with short term ethical concerns around any usage of existing commercial tools that fulfill a need. So gradeX development work is going to go on hold, while I bury myself in my keyboard again to deliver an open-source remote laboratory infrastructure over the coming months. I’ve a few other things up my sleeve as well … but more about those in good time!