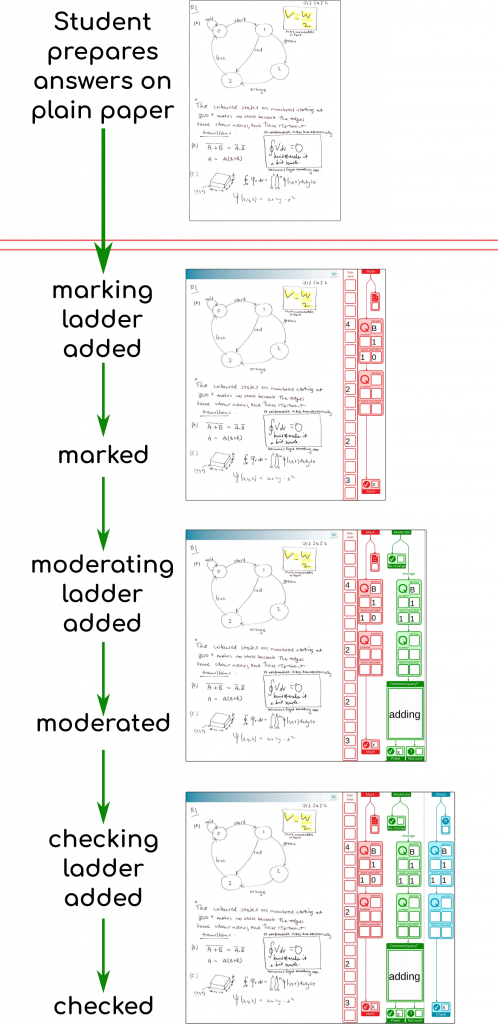
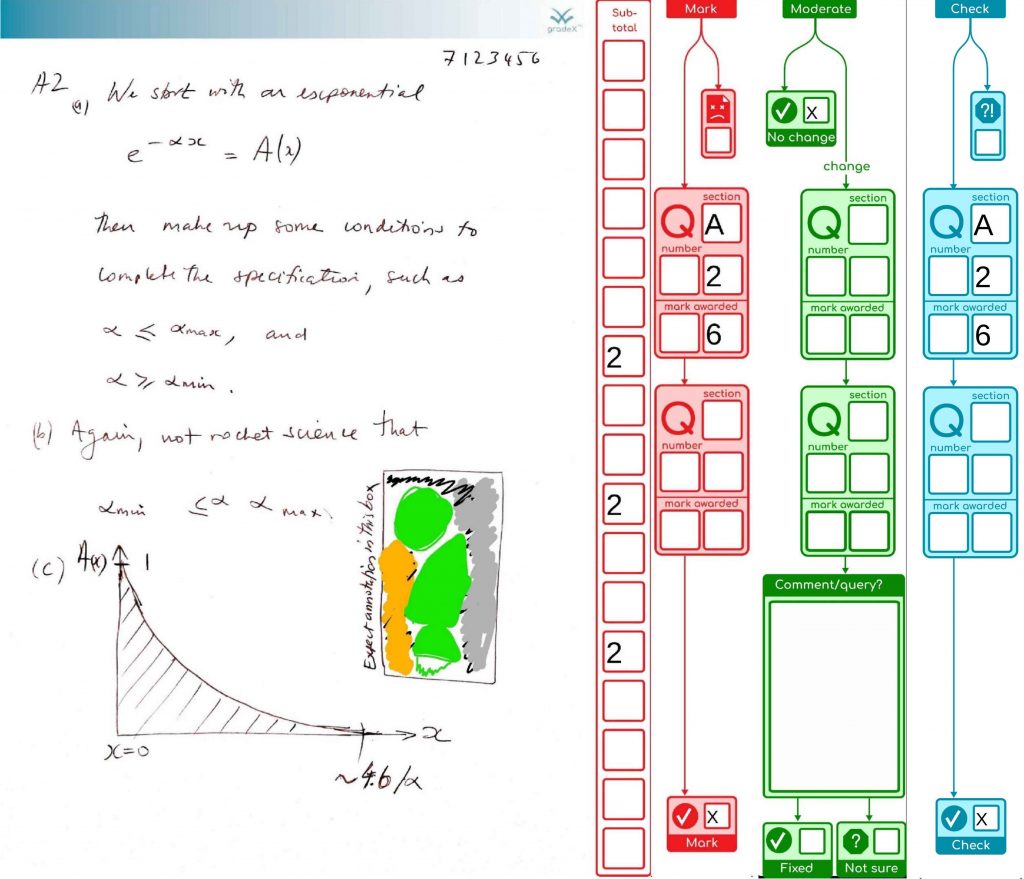
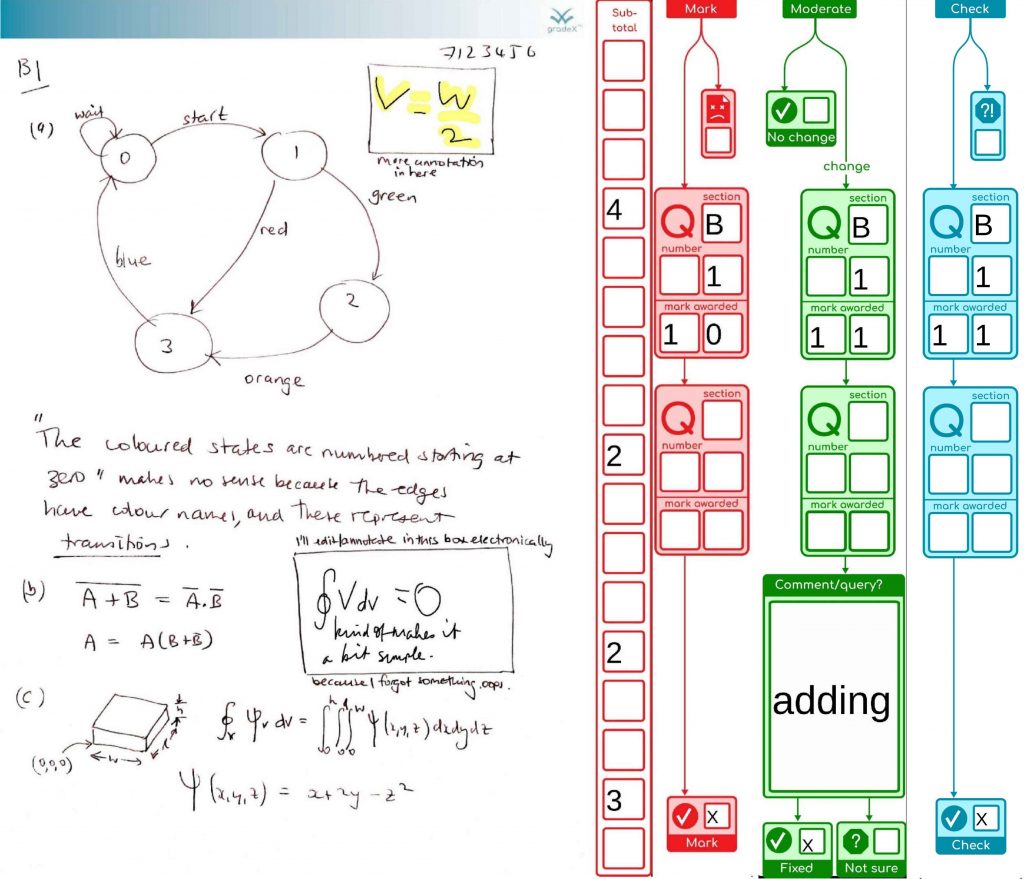
This is just a “quick” update as we approach the next exam diet (Semester One, Academic Year 2020/2021 Northern Hemisphere). Short story, we’re jumping ship to the original plan. Read on for why, but first a reminder to those involved that we did a good thing, for good reasons, and time and context have changed, not the reasons for doing what we did, when we did it. (In the same situation, I’d do the same thing again).
There were a lot of really good things about doing this project the way it was done, that were specific to the situation we were in (pandemic, no access to a particular commercial tool, and the short time frame requiring a certain kind of risk management – i.e. don’t hide data in a non-human format or store it in a fragile place, so we don’t put student or staff work at risk if the tool breaks unexpectedly). But it did take a dedicated team of three of us to process the exams – often I was coding and testing features until 3:00, 4:00am or later, then they were going straight into production with one of our team using them from 7:00am or so. That was fun, but hard work.
Looking back, I still can’t quite believe the quantity of features, or level of detail that things got to, with this project … perhaps with the lack of sleep I wasn’t forming memories too well … but if a thing needs fixing, it needs fixing properly, so you can sleep at night (even if that is just for a an hour or two before you are bug-fixing your latest release), and that means handling detail.
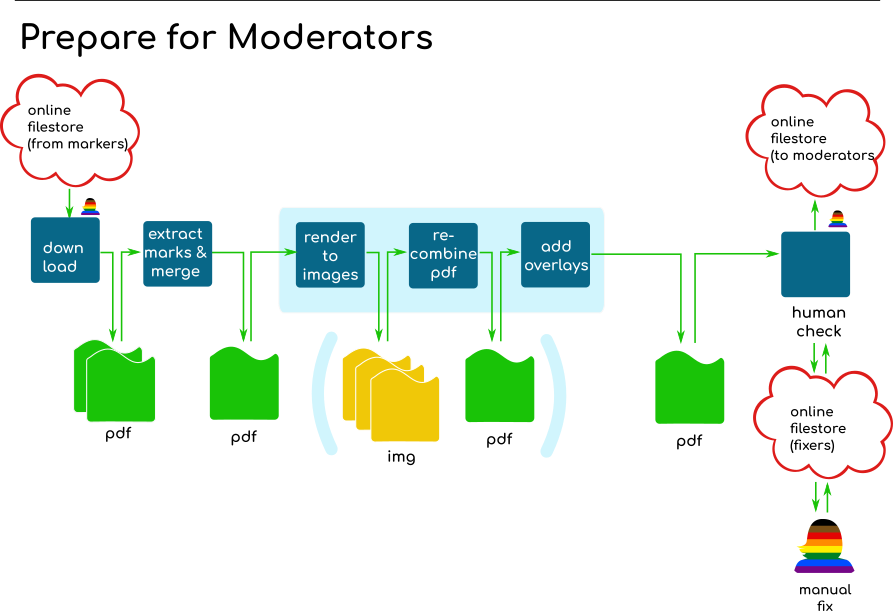
One of the least rewarding aspects of this project was that the risk management strategy forced us to upload and download a lot of redundant data (all the images in the PDF exam copies had to go with the document everywhere, even if the new data added by a marker was just a few hundreds of text characters), and to add to our pain, we had decided to use a typical corporate data store that was at times, how shall we say, vexing and tiresome. There were also the inevitable human behaviour challenges – ideally, users shouldn’t need to read instructions (it’s a nice ideal, at least), nor should they be able to mess things up when they are trying to be a good actor. But relying on an eco-system like PDF, across a lot of devices, with a lot of patchy implementations of the standard was probably the thing that the biggest issue for me. With PDF there is no way you can script in the level of interactive guidance that you can with javascript on the web, and you can’t control what software a user wants to use. And that can be a major issue ….
For example, when a user misses instructions not to do so (not really their fault, in my view), and uses the inbuilt software from a major premium brand of device supplier, which does not implement the spec correctly, and breaks your PDF parsing ability to the point it cannot actually understand the file (messing with the PDF catalogue is problematic for obvious reasons), then you have to get someone else to re-key the marking. At this point, you know you are at the limits of your ability to improve the user experience without moving away from PDF. When you are at the limit of the ecosystem like that, it’s not like more coding from you will help. Nor will tech testing, really, because how do you communicate all that to the users? It’s not like you can check the user agent and throw up some guidance on a better browser with the features you need, as you can do with the web.
So for this project, the issues of the ecosystem reliability, lack of control of user experience, and data overhead, mean it is now time to find a way to put on a web frontend and an online backend. That’s definitely possible but … the question is – would you really want to develop a whole new tool to do that when you can just buy one? Which is where we started – we had something we wanted to buy but couldn’t get it.
Well, more than half a year later, we’ve finally managed to get our mitts on the commercial tool we originally wanted, and others are now taking on the process of integrating it into our procedures. I’ve stepped back from that process because I want to get back to my first love, remote labs. Which I owe a whole shed load of long-overdue development time. Thanks to a great team of people at my current place, I now have a lab again for the first time in about two years to underpin that development work (There is more information on this project coming soon, to a different blog site which I’ll link here when it is up).

What does that mean for gradeX®? Well, astute Readers will have noticed the name is now registered. If you buy me a coffee post pandemic I’ll explain one of the other motivations for doing this, but mainly, it was a symbolic move to show the people that worked with me on this that what we did has laid the groundwork for some future goodness, which will remain true to the open-source, development-in-public approach of the project so far. For now, I think that future goodness needs to be something that adds to the tableau of marking codes out there, rather than duplicates (e.g. trying to compete with existing tools to do the same job). So, novel marking practices that are not adequately supported by existing tools are all potential candidates, with a possible aim being to support the piloting of a bunch of things related to authentic assessment and scale them up quickly if they are promising. It might be something to support some twist on evaluative judgment development, peer interaction, reflection or some other idea. I’m expecting those ideas to emerge from ongoing curriculum development efforts, and we’ll know when it is time to work on the software to support them. Meanwhile, if you find the unique combination of features in pdf.gradex to be useful, then remember, it is open-source, and remains available to use in the form that got us through >39,000 pages, although I won’t be available to hold your hand (unless you can make me an offer I can’t refuse, and chances are, you could get a commercial product for that sort of money). See the repo here https://github.com/timdrysdale/gradex-cli. Enjoy! Until the next update ….